Fabric Forumlarının En Sık Sorusu
Microsoft Fabric kullanıcılarının en çok tartıştığı konu şudur: _"Lakehouse mı, Warehouse mı kullanmalıyım?"_ Bu soru Microsoft Tech Community, Reddit r/PowerBI ve Stack Overflow'da her hafta onlarca kez soruluyor. Ve cevabı düşündüğünüzden daha nüanslı.
Bu rehberde, gerçek dünya projelerinden edindiğimiz deneyimlerle her iki yapının avantajlarını, sınırlarını ve en yaygın hataları ele alacağız.
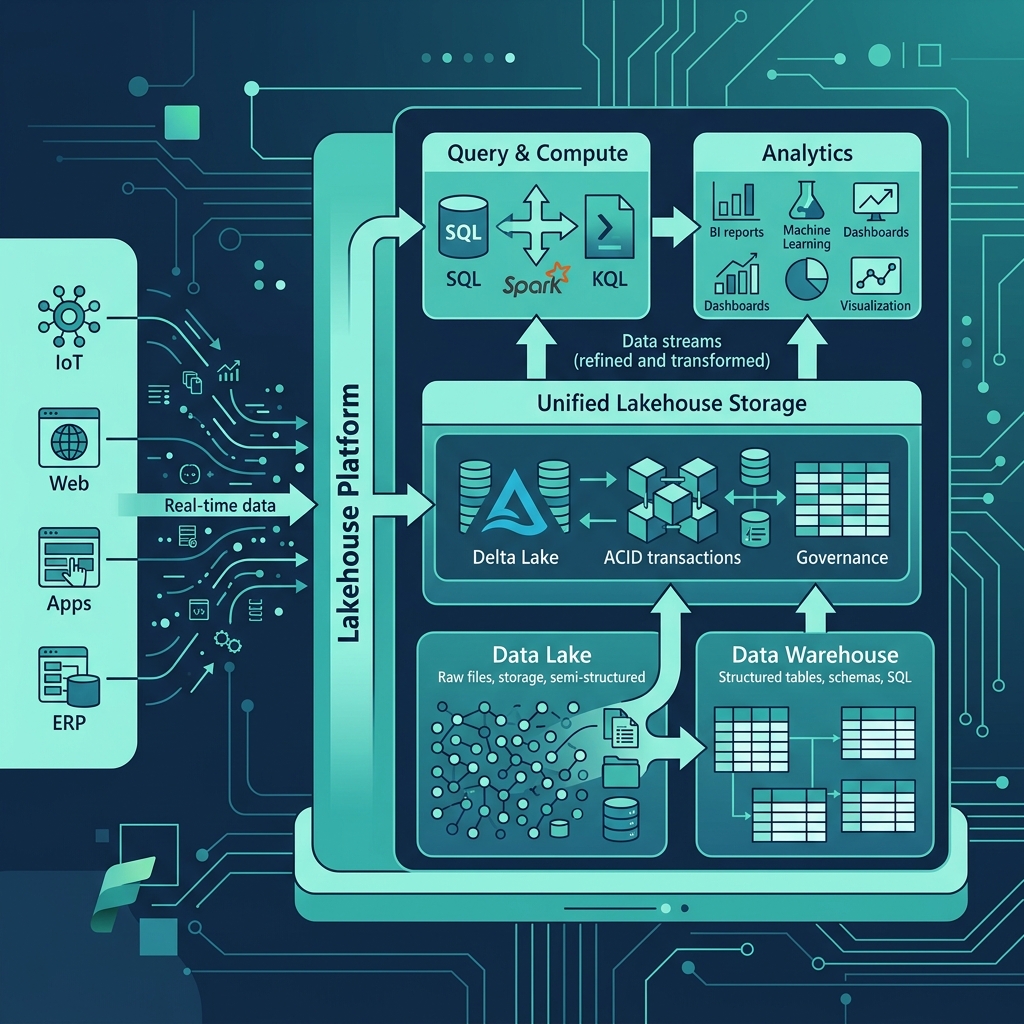
Lakehouse Nedir?
Fabric Lakehouse, Data Lake'in esnekliğini ve SQL Warehouse'ın yapısını tek bir yerde birleştirir. Veriler Delta/Parquet formatında OneLake'de saklanır ve hem Spark (Python/Scala) hem de SQL Endpoint üzerinden sorgulanabilir.
Lakehouse Güçlü Yanları
- Delta formatı: ACID transaction desteği, time travel, schema evolution
- Spark erişimi: Python, PySpark, Scala ile güçlü veri dönüşümü
- DirectLake modu: Import hızında, DirectQuery esnekliğinde — Power BI raporlarında devrim
- Maliyet: CU tüketimi Warehouse'a göre genellikle daha düşük
- Dosya desteği: CSV, JSON, Parquet, Avro gibi dosyaları doğrudan okuyabilme
Lakehouse Sınırları
- SQL Endpoint read-only — INSERT/UPDATE/DELETE yapılamaz
- Stored procedure ve view desteği yok (SQL Endpoint'te)
- T-SQL'e alışkın DBA'lar için öğrenme eğrisi var
Warehouse Nedir?
Fabric Warehouse, geleneksel SQL Data Warehouse deneyimini Fabric içinde sunar. T-SQL ile tam okuma/yazma desteği vardır. Stored procedure, view, schema yönetimi gibi klasik DWH özellikleri mevcuttur.
Warehouse Güçlü Yanları
- Tam T-SQL desteği: INSERT, UPDATE, DELETE, MERGE, SP, View
- DBA-friendly: SQL Server/Azure SQL deneyimine çok benzer
- Cross-database sorgulama: Birden fazla Warehouse ve Lakehouse'u tek sorguda birleştirebilme
- Security: Tablo ve kolon düzeyinde güvenlik
Warehouse Sınırları
- Spark erişimi yok — sadece T-SQL
- CU tüketimi daha yüksek olabilir
- Python/PySpark ile dönüşüm yapılamaz
Karşılaştırma Tablosu
| Özellik | Lakehouse | Warehouse |
|---|---|---|
| Veri yazma | Spark/Notebook/Dataflow | T-SQL (INSERT/UPDATE/DELETE) |
| Veri okuma | SQL Endpoint + Spark | T-SQL |
| Stored Procedure | ❌ | ✅ |
| View | ❌ (SQL Endpoint'te) | ✅ |
| Spark/Python | ✅ | ❌ |
| DirectLake | ✅ | ✅ |
| Dosya formatı | Delta/Parquet (+ CSV, JSON) | Delta/Parquet |
| Maliyet (CU) | Genellikle düşük | Genellikle yüksek |
| Öğrenme eğrisi | Spark bilgisi gerekir | SQL bilgisi yeterli |
Karar Ağacı
Forum'da En Sık Yapılan Hatalar
Hata 1: Her şeyi Warehouse'a koymak
Geleneksel DWH alışkanlığıyla tüm verileri Warehouse'a yükleyen ekipler, gereksiz CU tüketimine maruz kalır. Ham verileri Lakehouse'da tutup, sadece son katmanı (Gold) Warehouse'a koymak çok daha verimli.
class="code-comment"># Lakehouse'da Bronze → Silver → Gold katmanı
class="code-comment"># Bronze: Ham veri (Lakehouse Files bölümüne yükle)
class="code-comment"># Silver: Temizlenmiş veri (Notebook ile dönüştür)
df_silver = (spark.read.format(class="code-string">"delta").load(class="code-string">"Tables/bronze_satislar")
.filter(class="code-string">"Tutar > class="code-number">0")
.dropDuplicates([class="code-string">"SiparisID"])
)
df_silver.write.format(class="code-string">"delta").mode(class="code-string">"overwrite").save(class="code-string">"Tables/silver_satislar")
class="code-comment"># Gold: İş katmanı (Warehouseclass="code-string">'a veya Lakehouse'a)
df_gold = (df_silver
.groupBy(class="code-string">"UrunKategorisi", class="code-string">"Yil", class="code-string">"Ay")
.agg({class="code-string">"Tutar": class="code-string">"sum", class="code-string">"SiparisID": class="code-string">"countDistinct"})
)
df_gold.write.format(class="code-string">"delta").mode(class="code-string">"overwrite").save(class="code-string">"Tables/gold_satis_ozet")Hata 2: DirectLake'i anlamamak
DirectLake, Power BI'ın en heyecan verici özelliğidir ama forumlarda en çok kafa karışıklığı yaratan konu:
- DirectLake, Lakehouse ve Warehouse'dan doğrudan Delta dosyalarını okur
- Import gibi hızlı ama DirectQuery gibi her zaman güncel
- Fallback: Büyük tablolarda veya desteklenmeyen DAX'larda otomatik olarak DirectQuery'ye düşer
-- DirectLake fallback'i tetikleyen durumlar:
-- 1. Çok fazla satır (varsayılan limit: ~1.5 milyar)
-- 2. Desteklenmeyen DAX fonksiyonları
-- 3. RLS (Row Level Security) bazı senaryolarda
-- Fallback durumunu kontrol etmek için:
-- Semantic Model > Settings > DirectLake Behavior
-- "DirectLake Only" seçerseniz fallback olmaz ama hata alabilirsinizHata 3: Shortcut'ları yanlış kullanmak
OneLake Shortcuts, başka bir Lakehouse veya harici depolamadan (ADLS, S3) veri referanslama imkânı sunar — veriyi kopyalamadan. Ama forumda sık görülen hata: Shortcut üzerinden yoğun JOIN sorguları çalıştırmak. Bu durumda veriler ağ üzerinden çekildiği için performans çok düşer.
Hibrit Mimari: En İyi Uygulama
Pratikte çoğu kurumsal proje her ikisini de kullanır:
- Bronze/Silver: Lakehouse'da (Spark ile dönüşüm)
- Gold: İhtiyaca göre Lakehouse veya Warehouse
- Raporlama: DirectLake ile Power BI
Sonuç
Lakehouse vs Warehouse sorusunun cevabı "ikisi de" olabilir. Spark dönüşümü ve dosya esnekliği için Lakehouse, T-SQL ve SP desteği için Warehouse kullanın. Medallion Architecture (Bronze-Silver-Gold) ile katmanlı bir yapı kurarak her iki dünyanın da avantajlarından yararlanın. Önemli olan doğru katmanda doğru aracı kullanmak.