Microsoft Fabric Nedir?
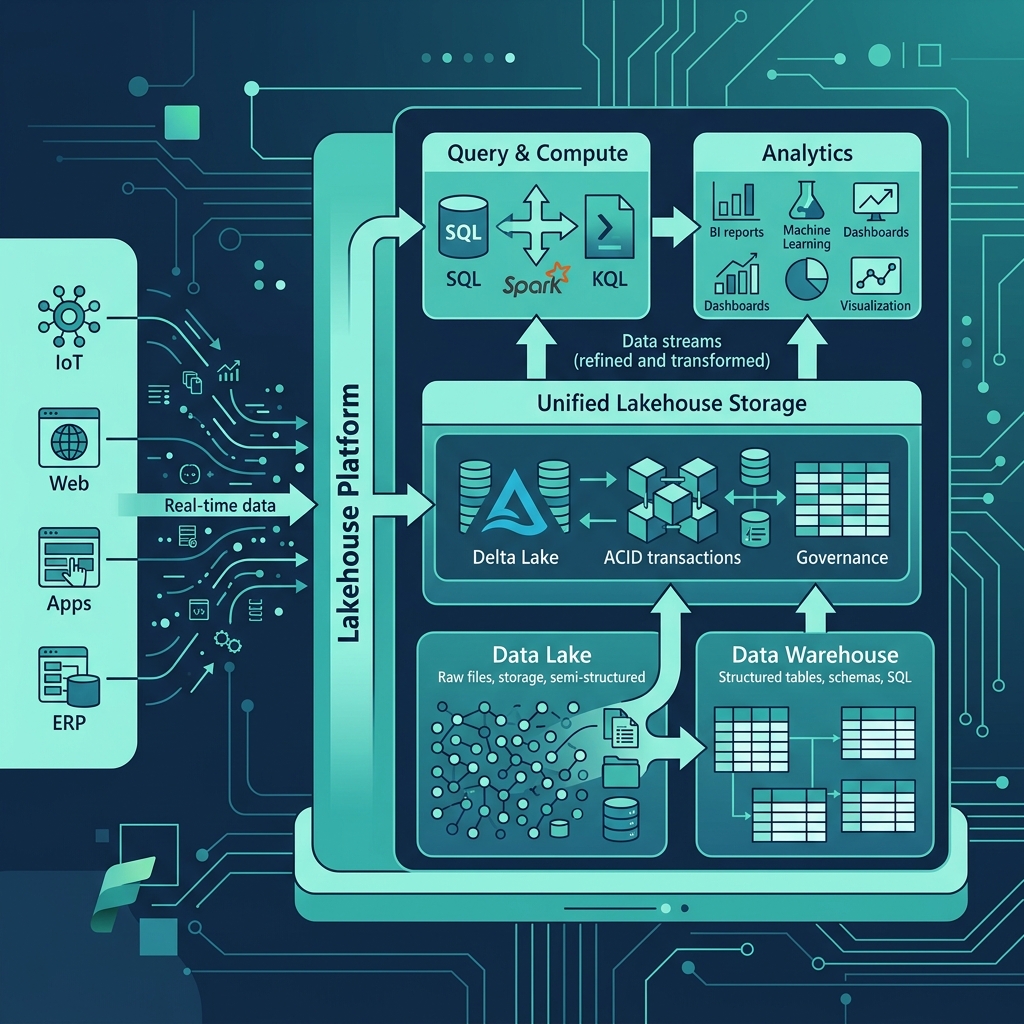
Microsoft Fabric, Microsoft'un 2023'te duyurduğu, uçtan uca veri analitiği platformudur. Power BI, Azure Data Factory, Azure Synapse Analytics ve daha birçok hizmeti tek bir SaaS çatısı altında birleştiren Fabric, veri mühendisleri, analistler ve iş kullanıcıları için birleşik bir deneyim sunar.
Fabric'in en büyük farkı: Artık farklı Azure servisleri arasında veri kopyalamanız, ayrı lisanslar yönetmeniz veya entegrasyon kodları yazmanız gerekmiyor. Tek bir kapasite, tek bir ortam, tek bir veri gölü.
Fabric Mimarisi: Bileşenler
OneLake: Tüm Verinizin Evi
OneLake, Fabric'in birleşik depolama katmanıdır. OneDrive'ın veri analitiği versiyonu gibi düşünebilirsiniz. Tüm Fabric iş yükleri — Lakehouse, Warehouse, Notebooks — aynı OneLake üzerinde çalışır. Bu sayede veri kopyalama ve taşıma ihtiyacı ortadan kalkar.
- Delta/Parquet formatı: Tüm veriler açık formatlarda saklanır
- Shortcuts: Başka depolama alanlarına (ADLS, S3) referans verme
- Tek güvenlik modeli: Veri erişim izinleri merkezi yönetilir
Lakehouse: En İyi İki Dünyanın Birleşimi
Lakehouse, Data Lake'in esnekliğini ve Data Warehouse'ın yapısını tek bir yerde birleştirir.
-- Fabric Lakehouse SQL Endpoint ile sorgulama
SELECT
p.KategoriAdi,
YEAR(s.SiparisTarihi) AS Yil,
SUM(s.Tutar) AS ToplamSatis,
COUNT(DISTINCT s.MusteriID) AS BenzersizMusteri
FROM lakehouse.Satislar s
JOIN lakehouse.Urunler p ON s.UrunID = p.UrunID
WHERE s.SiparisTarihi >= '2024-01-01'
GROUP BY p.KategoriAdi, YEAR(s.SiparisTarihi)
ORDER BY ToplamSatis DESC;Data Factory: Pipeline Tasarımı
Fabric'teki Data Factory, Azure Data Factory'nin gelişmiş versiyonudur. Görsel pipeline tasarımı ile verileri kaynaklardan çekip OneLake'e yükleyebilirsiniz.
Fabric vs Geleneksel Yaklaşım
| Özellik | Geleneksel (Azure) | Microsoft Fabric |
|---|---|---|
| Depolama | ADLS + SQL Server ayrı | OneLake (tek, birleşik) |
| ETL | Azure Data Factory | Data Factory (entegre) |
| Dönüşüm | Databricks / Synapse Spark | Notebooks (entegre Spark) |
| Raporlama | Power BI (ayrı lisans) | Power BI (dahil) |
| Yönetim | 5+ ayrı servis yönetimi | Tek portal |
| Maliyet | Her servis ayrı faturalanır | Tek kapasite birimi (CU) |
Fabric ile Veri Platformu Kurulumu
Sıfırdan bir Fabric platformu kurarken izlenecek adımlar:
Adım 1: Kapasite ve Workspace
Fabric kapasitesi, tüm iş yüklerinin (Data Factory, Lakehouse, Power BI) çalışacağı kaynak havuzudur. F2 (en küçük) ile başlayıp ihtiyaca göre büyütebilirsiniz.
Adım 2: Lakehouse ve Tablo Yapısı
class="code-comment"># Fabric Notebook - PySpark ile veri dönüşümü
from pyspark.sql import functions as F
class="code-comment"># Lakehouse'dan oku
df_satis = spark.read.format(class="code-string">"delta").load(class="code-string">"Tables/ham_satislar")
class="code-comment"># Dönüştür
df_temiz = (df_satis
.filter(F.col(class="code-string">"Tutar") > class="code-number">0)
.withColumn(class="code-string">"Yil", F.year(class="code-string">"SiparisTarihi"))
.withColumn(class="code-string">"Ay", F.month(class="code-string">"SiparisTarihi"))
.dropDuplicates([class="code-string">"SiparisID"])
)
class="code-comment"># Delta formatında yaz
df_temiz.write.format(class="code-string">"delta").mode(class="code-string">"overwrite").save(class="code-string">"Tables/temiz_satislar")Adım 3: Semantic Model ve Raporlama
Lakehouse veya Warehouse üzerinde Semantic Model (eskiden Dataset) oluşturun. DAX measure'ları burada tanımlanır ve Power BI raporları bu model üzerinden çalışır.
Forumlarda En Çok Sorulan Fabric Soruları
Fabric ile çalışmaya başlayan ekiplerin forumlarda en sık karşılaştığı sorunlar:
"Lakehouse mı Warehouse mı kullanmalıyım?"
Bu, Fabric'in 1 numaralı sorusudur. Kısa cevap: Spark/Python gerekiyorsa Lakehouse, T-SQL stored procedure gerekiyorsa Warehouse. Çoğu projede ikisini birlikte kullanırsınız — Medallion Architecture (Bronze-Silver-Gold) ile.
"DirectLake raporlarım neden yavaş?"
Muhtemelen DirectQuery'ye fallback yapıyor. Guardrail sınırlarını (satır sayısı, desteklenmeyen DAX) aştığınızda DirectLake sessizce DirectQuery moduna geçer. Semantic Model ayarlarından kontrol edin.
"Fabric faturamız çok yüksek geldi!"
Kapasite yönetimi yapılmadığında CU tüketimi hızla artar. Mesai dışı kapasiteyi duraklatmak, Notebook'ları optimize etmek ve Pipeline'ları düşük yük saatlerine planlamak %50'ye kadar tasarruf sağlar.
"Notebook'um aniden çok yavaşladı"
Büyük olasılıkla throttling. Aynı kapasitede başka bir ekip üyesi yoğun bir Pipeline veya Spark işi çalıştırdığında kapasite paylaşıldığı için performans düşer. Capacity Metrics App ile izleyin.
İlgili Yazılar
- Lakehouse vs Warehouse karşılaştırması → detaylı analiz ve karar ağacı
- DirectLake Modu rehberi → guardrails, fallback, V-Order optimizasyonu
- Fabric Kapasite Yönetimi → CU tüketimi, throttling, maliyet optimizasyonu
Sonuç
Microsoft Fabric, kurumsal veri platformu dünyasında paradigma değişikliği yaratıyor. Ayrı ayrı yönettiğiniz veri gölü, ETL, DWH ve raporlama araçlarını tek bir çatı altında birleştirerek karmaşıklığı azaltıyor, maliyeti düşürüyor ve değer üretme süresini kısaltıyor. SAP dışı kaynaklardan veri toplayan ve Microsoft ekosisteminde çalışan organizasyonlar için Fabric, modern veri platformu seçiminde güçlü bir aday.